面试官:今天要不来聊聊消息队列吧?我看你项目不少地方都写到Kafka了
候选者:嗯嗯
面试官:那你简单说明下你使用Kafka的场景吧
候选者:使用消息队列的目的总的来说可以有三种情况:解耦、异步和削峰
候选者:比如举我项目的例子吧,我现在维护一个消息管理平台系统,对外提供接口给各个业务方调用
候选者:他们调用接口之后,实际上『不是同步』下发了消息。
候选者:在接口处理层只是把该条消息放到了消息队列上,随后就直接返回结果给接口调用者了。
候选者:这样的好处就是:
候选者:1. 接口的吞吐量会大幅度提高(因为未做真正实际调用,接口RT会非常低)【异步】
候选者:2. 即便有大批量的消息调用接口都不会让系统受到影响(流量由消息队列承载)【削峰】

候选者:又比如说,我这边还有个项目是广告订单归因工程,主要做的事情就是得到订单数据,给各个业务广告计算对应的佣金。
候选者:订单的数据是从消息队列里取出的
候选者:这样设计的好处就是:
候选者:1. 交易团队的同学只要把订单消息写到消息队列,该订单数据的Topic由各个业务方自行消费使用【解耦】【异步】
候选者:2. 即便下单QPS猛增,对下游业务无太大的感知(因为下游业务只消费消息队列的数据,不会直接影响到机器性能)【削峰】
面试官:嗯,那我想问下,你觉得为什么消息队列能到削峰?
面试官:或者换个问法,为什么Kafka能承载这么大的QPS?
候选者:消息队列「最核心」的功能就是把生产的数据存储起来,然后给各个业务把数据再读取出来。
候选者:跟我们处理请求时不一样:在业务处理时可能会调别人的接口,可能会需要去查数据库…等等等一系列的操作才行
候选者:像Kafka在「存储」和「读取」这个过程中又做了很多的优化
候选者:举几个例子,比如说:
候选者:我们往一个Topic发送消息或者读取消息时,实际内部是多个Partition在处理【并行】
候选者:在存储消息时,Kafka内部是顺序写磁盘的,并且利用了操作系统的缓冲区来提高性能【append+cache】
候选者:在读写数据中也减少CPU拷贝文件的次数【零拷贝】

面试官:嗯,你既然提到减少CPU拷贝文件的次数,可以给我说下这项技术吗?
候选者:嗯,可以的,其实就是零拷贝技术。
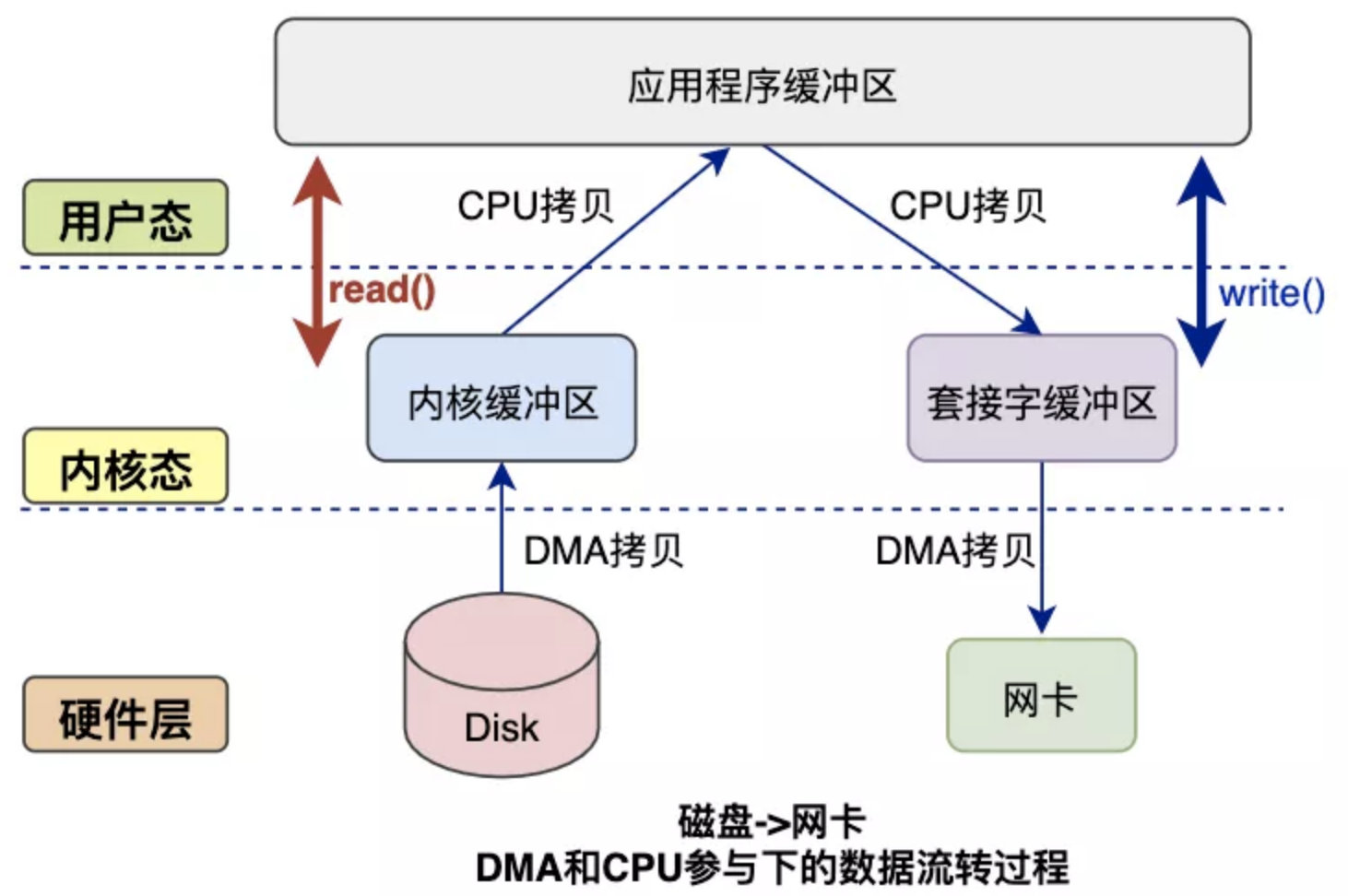
候选者:比如我们正常调用read函数时,会发生以下的步骤:
候选者:1. DMA把磁盘的拷贝到读内核缓存区
候选者:2. CPU把读内核缓冲区的数据拷贝到用户空间
候选者:正常调用write函数时,会发生以下的步骤:
候选者: 1. CPU把用户空间的数据拷贝到Socket内核缓存区
候选者: 2. DMA把Socket内核缓冲区的数据拷贝到网卡
候选者:可以发现完成「一次读写」需要2次DMA拷贝,2次CPU拷贝。而DMA拷贝是省不了的,所谓的零拷贝技术就是把CPU的拷贝给省掉
候选者:并且为了避免用户进程直接操作内核,保证内核安全,应用程序在调用系统函数时,会发生上下文切换(上述的过程一共会发生4次)
候选者:目前零拷贝技术主要有:mmap和sendfile,这两种技术会一定程度下减少上下文切换和CPU的拷贝
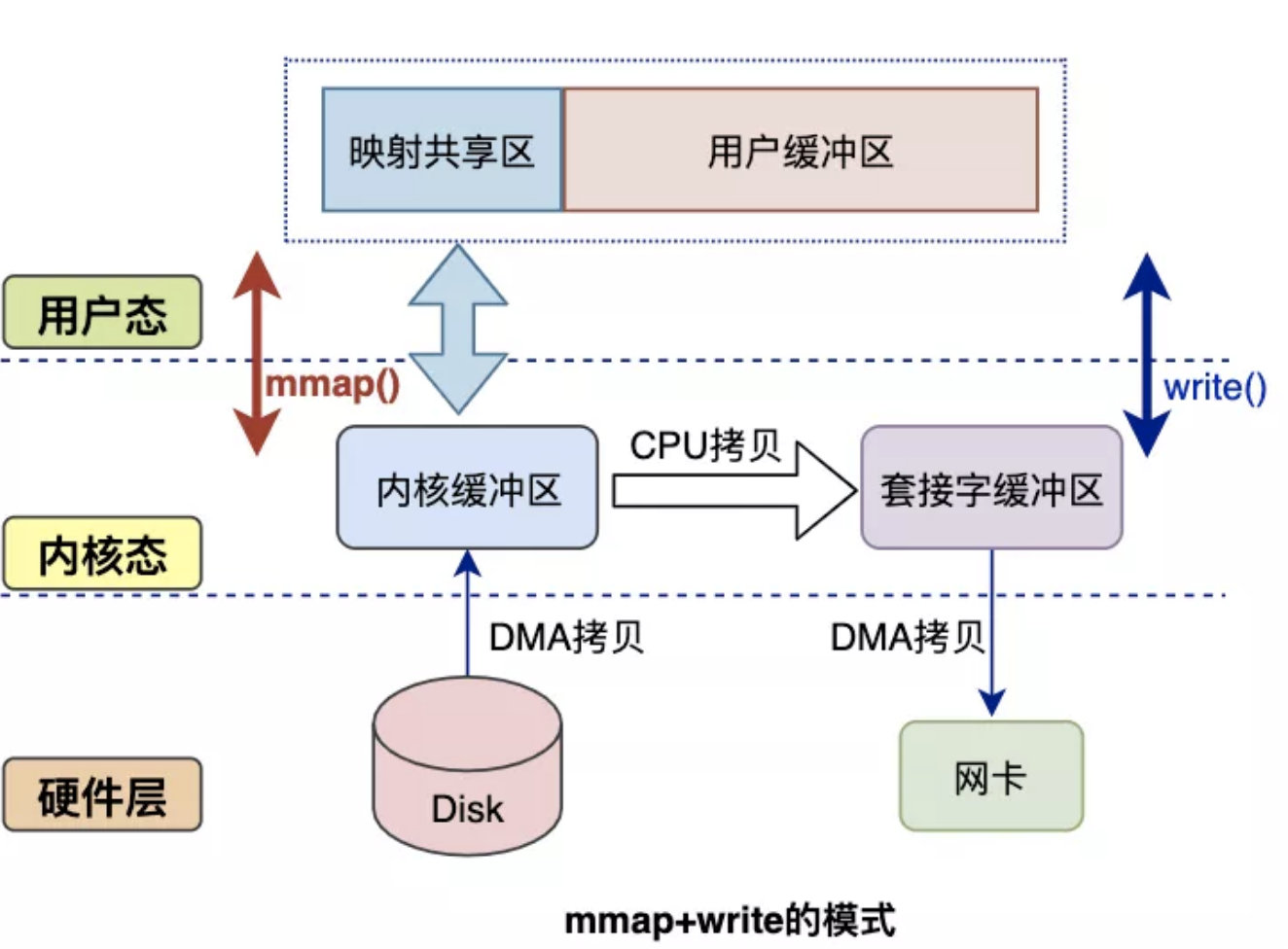
候选者:比如说:mmap是将读缓冲区的地址和用户空间的地址进行映射,实现读内核缓冲区和应用缓冲区共享
候选者:从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝
候选者:使用mmap的后一次读写就可以简化为:
候选者:一、DMA把硬盘数据拷贝到读内核缓冲区。
候选者:二、CPU把读内核缓存区拷贝至Socket内核缓冲区。
候选者:三、DMA把Socket内核缓冲区拷贝至网卡
候选者:由于读内核缓冲区与用户空间做了映射,所以会省了一次CPU拷贝
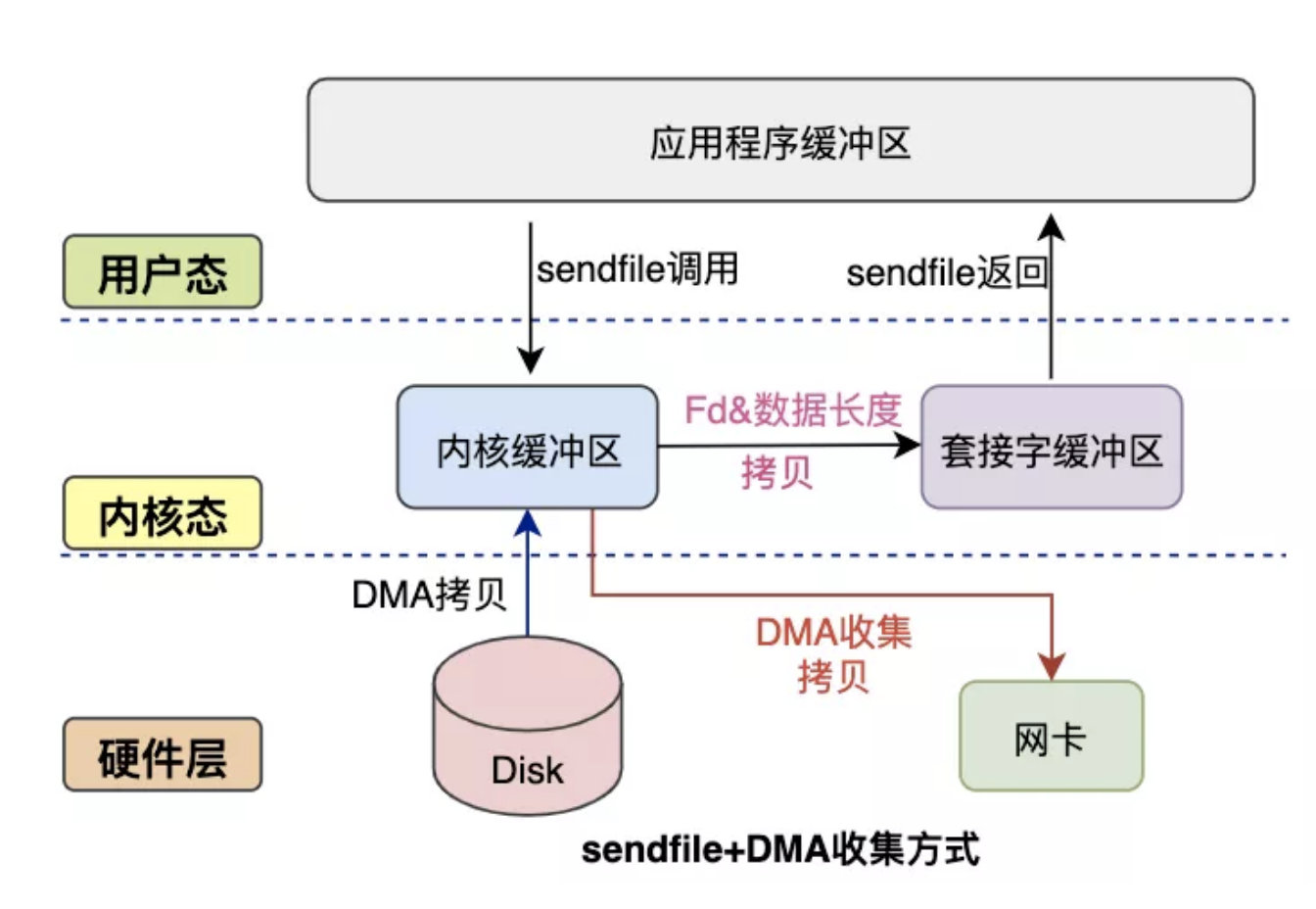
候选者:而sendfile+DMA Scatter/Gather则是把读内核缓存区的文件描述符/长度信息发到Socket内核缓冲区,实现CPU零拷贝
候选者:使用sendfile+DMA Scatter/Gather一次读写就可以简化为:
候选者:一、DMA把硬盘数据拷贝至读内核缓冲区。
候选者:二、CPU把读缓冲区的文件描述符和长度信息发到Socket缓冲区。
候选者:三、DMA根据文件描述符和数据长度从读内核缓冲区把数据拷贝至网卡
候选者:回到Kafka上
候选者:从Producer->Broker,Kafka是把网卡的数据持久化硬盘,用的是mmap(从2次CPU拷贝减至1次)
候选者:从Broker->Consumer,Kafka是从硬盘的数据发送至网卡,用的是sendFile(实现CPU零拷贝)
面试官:我稍微打断下,我还有点事忙,我总结下你说的话吧
面试官:你用Kafka的原因是为了异步、削峰、解耦
面试官:Kafka能这么快的原因就是实现了并行、充分利用操作系统cache、顺序写和零拷贝
面试官:没错吧?
候选者:嗯
面试官:ok,下次继续面吧, 我这边有点忙

第一时间获取BATJTMD一线互联网大厂最新的面试资料以及内推机会关注公众号「对线面试官」
